





Our earliest employees had a lot of experience getting journal content into an acceptable format in order to develop reliable journal services. The standard in development then was the National Library of Medicine’s XML format. This document model proposed standard ways to identify key data about the article’s sources, the journal issue, the publisher, and the authors, called metadata.
Over time, the NLM standard evolved into the Journal Article Tag Suite (JATS), which codified document metadata for all of these key aspects of an article. The JATS content model now is a NISO standard used to “tag” content elements of millions of articles in thousands of publications around the world. In no small part, Atypon has driven JATS adoption for all our publishers, and in turn, publishers around the world are now expected to provide JATS to many different publishing platforms, including for articles submitted to journals, some conferences, and downstream indices such as PubMed.
What advantages does a global standard provide?
From a technology standpoint, if the “content” items (all the journal article’s metadata, body text, figures, tables, and references) are reliably based on the same XML content model, then each platform or service is free to develop its own presentation, delivery, and distribution of the content. This content standardization is like getting all the phone companies to agree on a global standard for delivering the content of phone audio, text, and multimedia. Once a global standard has been achieved, everyone has a solid base to build upon.
The ecosystem of article and journal services has flourished in conjunction with JATS adoption. Google Scholar, PubMed, Crossref, and AI services that gather and curate data from scholarly publications all benefit from the standardization of the metadata in journal articles. Well-known examples include ORCID for disambiguating contributors, CRediT for identifying specific contributions, and Ringgold and ROR for identifying institutional and organizational identities persistently.
In scholarly publishing, when a publisher moves from a home-grown, proprietary content model to JATS, they are free to look at all platforms and services based on this global model to choose what works best for them.
What is a Document Type Definition (DTD), and what does it do?
There are different ways to provide the rules for applying XML tags to articles. The JATS content model used by most publishers today is a DTD content model. (Some publishers use the alternative JATS content model called “JATS Schema,” which is the same DTD content model expressed in a different notation: XSD or RNG.)
Each structural component of the DTD is called an element (also commonly called a “tag”). Elements can carry descriptors in attributes. For example, the element <article> has an attribute article-type, which specifies if it is a research-article, correction, letter, book-review, etc.
A DTD states the rules for the hierarchy, the sequence, the occurrence, and the content that can be contained in every part of the document. Files that follow these rules are called “valid” to the DTD.
| hierarchy example | JATS provides for an outer <article> which then contains the <front>, <body>, and <back>. All metadata about the article goes in the <front>, the main article content in the <body>, and the references in the <back>. |
| sequence example | The JATS DTD states that the <front> must occur before the <body> and the <body> must occur before the <back>. |
| occurrence example | A JATS article can have only one <front>, but inside the article metadata, there can be many contributors. |
| content example | Most JATS elements can contain other elements, such as the <surname> and <given-names> of an individual author. A few elements in JATS do not permit any “child” element, only permitting some text in the tag. |
Some structures are optional, as this diagram shows:
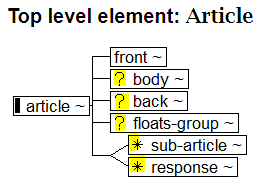
A ? indicates that the element is optional and can occur only once if used. A * indicates that the structure is optional but can occur one or more times when used. So you can see that an article only requires the <front> element structure. An article with <front> and <back> only (for metadata and references) would be valid.
Atypon supports older NLM v2+ journal DTDs, as well as JATS 1.0, 1.1, and 1.2 versions of the Archiving and Interchange version of JATS DTD (the most flexible version of the JATS content model).
How does the Literatum platform check the XML?
The first thing that the Literatum platform checks is whether the XML file is valid to the JATS DTD declared in the XML. If not, a “FATAL” error occurs, and the file is not accepted.
After that, the platform code checks many aspects of the XML tags in the file, looking for key metadata, such as an article ID, contributor names, the presence of journal and publisher data, and an article title. These checks for specific pieces of content are necessary because many elements in the JATS DTD are actually optional, so an XML file can be valid to the JATS DTD, yet still lack key metadata.
When a problem is found, we provide a specific error message to the content submitter so that they can review the problem and fix and resubmit the file. The message can be sent by email to the publisher’s team members, or to a vendor who has been authorized to submit content on behalf of a publisher.
How do we keep our clients synchronized with the JATS DTD changes?
A key member of our team, Nikos Markantonatos, is a voting member of the NISO Standing Committee for the JATS content model, as well as participating in JATS-related working groups. When a new version of JATS is in draft, not yet published, we evaluate the differences from the last version and start planning for support of new elements and attributes.
We don’t require Literatum publishers to use the latest standard version of JATS, but we do encourage it. For example, JATS 1.2 is the version we recommend for all publishers going forward, and when JATS 1.3 is officially published as the new standard version, we will provide support for it and recommend it for all content going forward across our current and our new clients.
If you would like to know more about JATS, please indicate your interest here. We would be delighted to include you in a new interest group that will also include some of our own XML enthusiasts.